Page hit count with AWS
This is part 2 of a series of article I'm planning to write about the cloud resume challenge.
You can find the first part where I explain how I host my website on AWS.
In this section, I'll provide some information about how I implemented the page counter, with the CDK.
Goals
Stricly speaking, the cloud resume challenge only requires to display the number of hits on the resume page. I thought it'd be interesting to add functionnalities to the challenge!
- Display the number of hits for all blog articles, in addition to the resume page
- Display an aggregate number of hits for all pages
- Add a Like button to all pages.
- Display the number of unique visitors for each page.
In this article, I'll discuss the first point, and revisit other points in future posts.
Database
We'll store all the statistics in a DynamoDB table: StatisticsTable.
To design a DynamoDB table, let's define the access patterns we have identified so far:
- Get a single article statitics (hits, likes, unique visitors)
- Increment the number of hits for an article (that will also increment the number of aggregated hits)
- Increment the number of likes for an article
- Increment the number of unique visitor for an article
- Get the aggregated hit count for the website
While I won't implement them all now, it's good to be aware of them so I can plan the database design accordingly.
Get a single article statistics
An article can be identify by its slug, the string that defines it in the url. For example, the slug for this article is cloud-resume-challenge-2.
I'll store the statistics of an article in a single row:
| PK | SK | Hits | Likes | UniqueVisitors |
|---|---|---|---|---|
| ARTICLE#<slug> | ARTICLE#<slug> |
I'm using both a partition and a sort key since I'm not sure what my future needs are going to be.
I'm also adding the ARTICLE prefix to the partition key, since I may add more data types to the table.
Here's an example of what the table would look like for this article:
| PK | SK | Hits | Likes | UniqueVisitors |
|---|---|---|---|---|
| ARTICLE#cloud-resume-challenge-2 | ARTICLE#cloud-resume-challenge-2 | 128 | 6 | 19 |
Get the aggregated hit count for the website
The aggretated hit count for the website a singleton. There'll be only a row to keep track of the website statistics.
I'll model it like this:
| PK | SK | Hits |
|---|---|---|
| TOTAL | TOTAL |
For now, I'll just add the Hits attribute, since it's the only statistics I want t track, but I might add more later.
Lambda
Since the lamdbas are implemented with NodeJS and TypeScript, I used the CDK construct NodejsFunction.
Some points are worth noting:
First, since I don't want to keep the logs any longer than necesary (to minimize cost), I set the log retention to 1 week.
Second, the lambda code will execute against the DynamoDB table, created by the CDK. There is no way for the Lambda code to know the name of the table generated by the CDK, so I pass the name of the table as a environment variable.
See the code below:
/* CDK */
const statisticsTable = new dynamodb.Table(this, "StatisticsTable", {
partitionKey: { name: "PK", type: dynamodb.AttributeType.STRING },
sortKey: { name: "SK", type: dynamodb.AttributeType.STRING },
billingMode: dynamodb.BillingMode.PAY_PER_REQUEST,
});
const getArticleStatisticsLambda = new lambda_nodejs.NodejsFunction(
this,
"GetArticleStatistics",
{
entry: join(__dirname, "..", "api", "statistics", "get.ts"),
handler: "handler",
logRetention: logs.RetentionDays.ONE_WEEK,
environment: {
TABLE_NAME: statisticsTable.tableName,
},
}
);
statisticsTable.grantReadData(getArticleStatisticsLambda);
/* LAMBDA */
const TABLE_NAME = process.env.TABLE_NAME!;
const dbClient = new DynamoDB.DocumentClient();
export const handler: APIGatewayProxyHandler = async (event, context) => {
const params = {
TableName: TABLE_NAME,
...
};
const item = await dbClient.get(params).promise();
...
};
In the code above, notice that I provide the lambda with the read access only to the DynamoDB table, via the grantReadData method. That's the principle of least privilege from AWS.
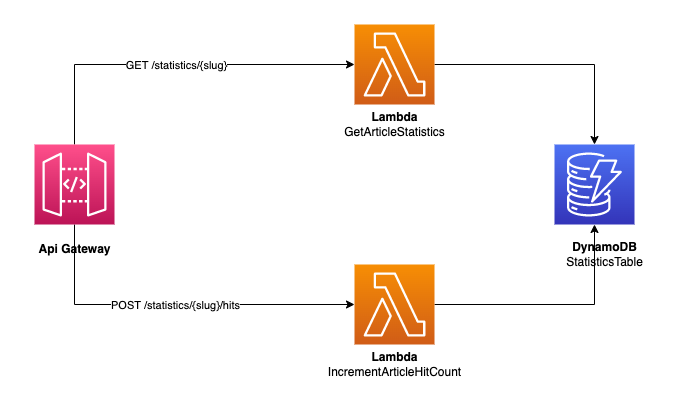
API Gateway
The Lambas are hooked to an API Gateway. The supported routes are:
GET /statistics: return the statistics for the whole website, ie the aggregated hit countGET /statistics/{slug}: return the statistics for a specific article, identified by its slugPOST /statistics/{slug}/hits: increments the hit count for a specific article
In order to keep things simple, the Lambdas are integrated with the LambdaIntegration construct.
Cors
I want to support only two origins for my api: the production domain and the localhost (so I can test locally).
In order to do so, I created this helper function:
const allowedOrigins = ["https://www.benoitpaul.com", "http://localhost:3000"];
export const getHeaders = (event: APIGatewayProxyEvent) => {
const origin = event.headers.Origin || event.headers.origin;
const validOrigin = allowedOrigins.find((allowedOrigin) =>
origin?.match(allowedOrigin)
);
if (!validOrigin) {
console.log(`invalid origin: ${origin}`);
}
return {
"Content-Type": "application/json",
"Access-Control-Allow-Origin": validOrigin || allowedOrigins[0],
};
};
This function will be called from the Lamda and the headers will be added to the response.
/* LAMBDA */
export const handler: APIGatewayProxyHandler = async (event, context) => {
try {
...
return {
statusCode: 200,
headers: getHeaders(event),
body: ...
};
} catch {
return { statusCode: 500, body: "Internal error" };
}
};
Conclusion
At the end of this chunk I have a website that records and display the number of hits for each article.
Here is a diagram of the infrastructure:
You find find the CDK for statistics stack on Github.